While learning a new technology or framework, I always like to build small but well covering Proof Of Concept application. It is even better if one can combine several new technologies into such a project. This is description of one such project which uses RavenDB, WebAPI, KnockoutJS, Bootstrap, D3JS.
Source code is available on GitHub
The Use Case
Everyone renting an apartment or any other property knows that it might be quite difficult to track the expenses and income in order to assure himself of the rent-ability of the given property. I have created an applications which helps with just that and thanks to this applications I was able to lern the mentioned technologies. Now let's take a look at them closer.
- KnockoutJS - to glue the interaction on the client side. Knockout is one of the cool JavaScript MV(*) frameworks which provide a way to organise and facilitate the JavaScript development. Unlike other frameworks (Backbone or Ember) KnockoutJS concentrate itself only on binding of the data and actions between the GUI (HTML) and the ViewModel (JavaScript) and does not take care for other aspects (such as client side routing). The framework is very flexible and allows you to bind almost anything to any DOM's elenent value or style.
- RavenDB - to stored the data. RavenDB is a document database, which seamlessly integrates into any C# project.
- WebAPI - to serve the data through REST services. WebAPI is a quite new technology from MS which is meant to provide better support for building REST services. Of course we have built REST services with WCF before, so the questions is why should we change to WebAPI? WCF was created in the age of WSDL. It was adapted later to generate JSON, however inside it still uses XML as data transformation format. WebAPI is complete rewrite which also provides other interesting features.
- Bootstrap - to give it a decent GUI. As its name says, bootstrap enables a quick development of a web application's GUI. It is a great tool to all of us who just want to get the project out and we still need a decent user interface.
- D3.js - to visualize data using charts. D3JS is a JavaScript library enabling the user to manipulate the DOM and SVG elements.
- KoExtensions - very small set of tools which I have created, allowing easy creation of pie charts or binding to google maps while using KnockoutJS.
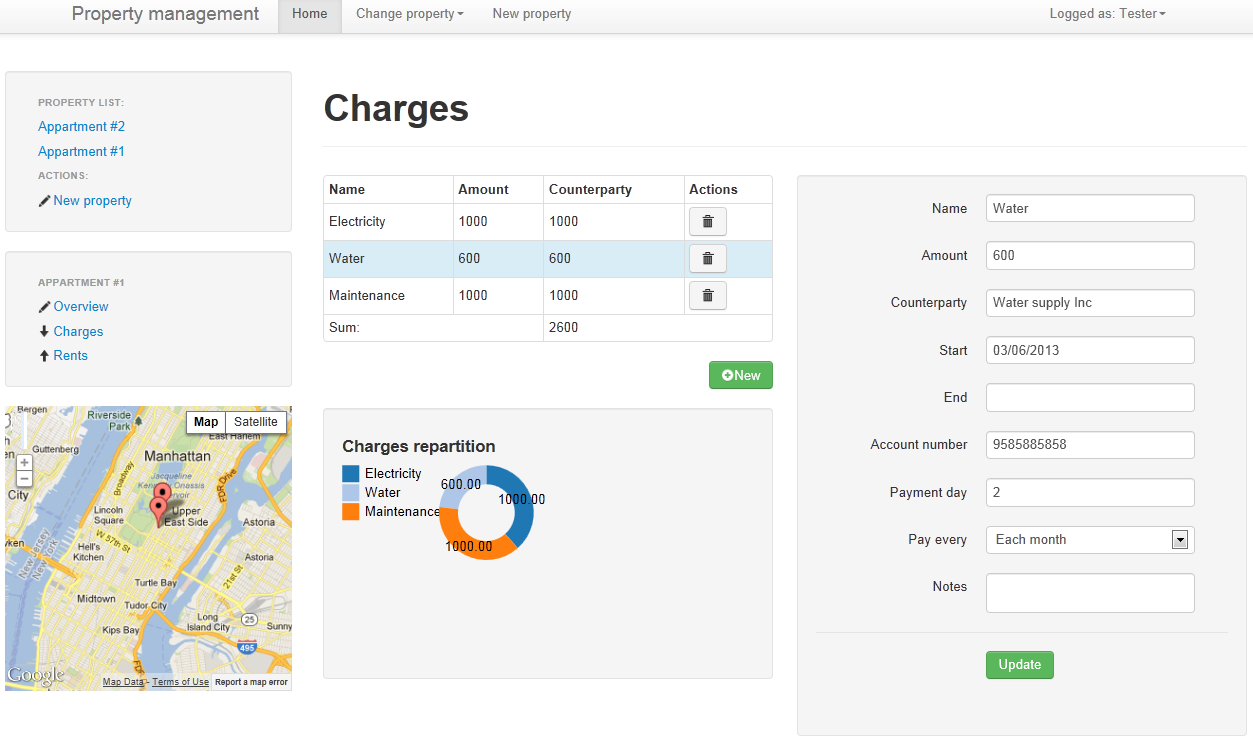
Here is how it looks like at the end:
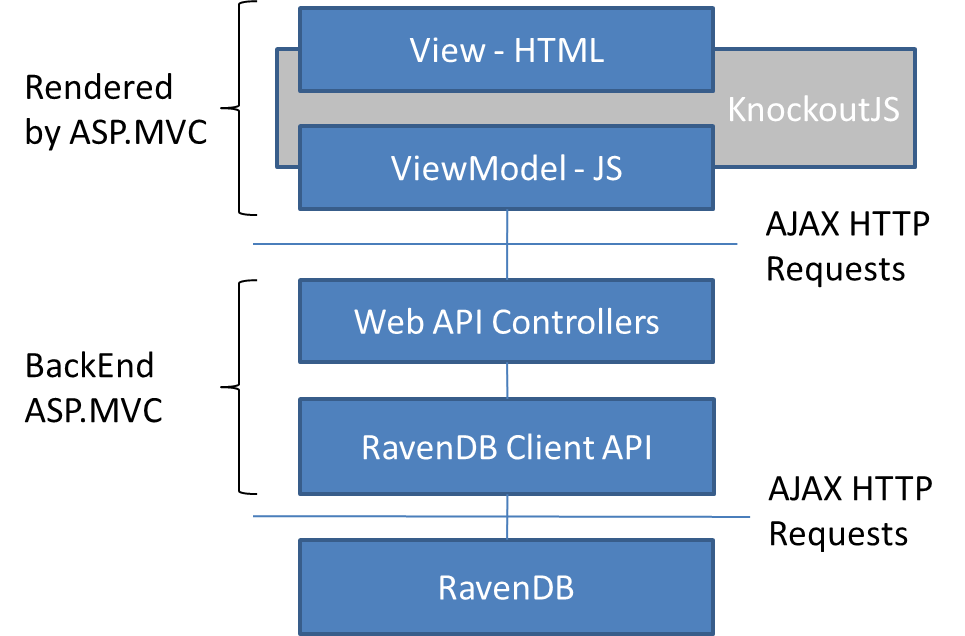
The architecture of the application
The architecture is visualized in the following diagram. The backend is composed of MVC application, which exposes several API controllers. These controllers talk directly to the database through RavenDB IDocumentSession interface. The REST services are invoked by ViewModel code written in JavaScript. The content of the ViewModels is bound the view using Knockout.
This application is as lightweight as possible. It is composed of a MVC 4 application with two types of Controllers: Standard and API. Standard controllers are used to render the base web pages.
Even though that this applications uses client side MVVM, the Html and JavaScript of the client side app have to be hosted in some server side application. I have chosen to host the applications inside the classic ASP.MVC application, but I could as well choose to use standard ASP.NET application.
But as many on the web I prefer MVC style applications. It is not a sin to mix server and client side MVC in one application.
This application has no service layer. All the logic can be found inside the Controllers. The controllers all use directly the
IDocumentSession of RavenDB to access the database. The correct approach to user RavenDB when using ASP.MVC is described on
the official web page. Basically the RavenDB session is opened when the controller's action is started and is closed when the action terminates. The structure of API controller however differs a little bit, but the principle is the same.
When to use Knockout or client side MV*
There are probably a lot of people around there with exactly the same question. It basically comes to the answer of whether to use or not any client side MVC JavaScript framework. From my purely personal point of view this makes sense when one or more of these conditions are met:
- You have a good server side REST API (or you plan to build one) and want to use it to build a web page.
- You are building more web-application then a website. That is to say, your users will stay at the page for some time, perform multiple actions, keep some user state and you need a responsive application for that.
- You need a really dynamic page. Even if you would use server side MVC than you would somehow need to include a lot of JavaScript for the dynamics of the page.
This is just my personal opinion and there is a lot of discussion around internet and as usually no silver-bullet answer.
Data model
RavenDB is NoSQL database, or as it would be better to say non-relational database. The data is stored in document collections, serialized to JSON. Each document contains an object or more specifically graph of objects serialized to JSON.
When working with relational databases, the aggregated graph of objects which is served to the user is usually constructed by several joins into several tables. On the other hand when working with document databases, the data which is aggregated into one object graph, should be also stored that way.
In our particular example, one property or asset can have several rents and several charges. One rent does not really have sense without the asset to which it is attached. That's why the rents and charges are stored directly inside each asset. This applications is composed of two collections: Owners and Assets. Here are examples of Owner and Asset document.
{
"Name": null,
"UserName": "test",
"Password": "test"
}
{
"OwnerId": 1,
"LastChargeId": 5,
"LastRentId": 0,
"Name": "Appartment #1",
"Address": "5th Ave",
"City": "New York",
"Country": "USA",
"ZipCode": "10021",
"Latitude": 40.774,
"Longitude": -73.965,
"InitialCosts": 0.0,
"Rents": [],
"Charges": [
{
"Counterparty": "New York Electrics",
"Type": null,
"Automatic": false,
"Regularity": "MONTH",
"Id": 2,
"Name": "Electricity",
"PaymentDay": 4,
"AccountNumber": "9084938890-2491",
"Amount": 1000.0,
"Unit": 3,
"Notes": "",
"End": "2013-03-19T23:00:00.0000000Z",
"Start": "2013-03-10T23:00:00.0000000Z",
},
{ ... },
{ ... }
],
"Ebit": 0.0,
"Size": 80.0,
"PMS": 1250000.0,
"Price": 100000000.0,
"IncomeTax": 0.0,
"InterestRate": 0.0
}
One question you might be asking yourself is why did I not use only one collection of Owners. Each Owner document would than contain all the assets as an inner collection. This is just because, I thought it might make sense in the future, to have an asset shared by two owners. The current design allows us anytime in the future, connect the asset to an collection of Owners, simply by replacing OwnerID property with and collection of integers, containing all the ids of the owners.
The Backend
The backend is composed by set of REST controllers. Here is the provided API:
- GET api/assets - get the list of all the appartment of current user
- DELETE api/asset/{id} - removing existing asset
- PUT api/asset - adding new asset
- PUT api/charges?assetID={id} - add new charge to existing asset
- POST api/charges?assetID={id} - update existing charge in given asset
- DELETE api/charge/assetID={id}?assetID={assetID} - removing charge from existing asset
-
PUT api/rents/?assetID={id} - add new charge
- POST api/rents/?assetID={id} - update existing charge
- DELETE api/rents/assetID={id}?assetID={assetID} - removing rent from existing asset
Getting all the assets
Without further introduction let's take a look at the first Controller which returns
all the apartments of the logged owner. This service is available at
api/assets url.
[Authorize]
public IEnumerable<Object> Get()
{
var owner = ObtainCurrentOwner();
var assets = GetAssets(owner.Id);
return result;
}
protected Owner ObtainCurrentOwner()
{
return RavenSession.Query<Owner>().SingleOrDefault(x => x.UserName == HttpContext.Current.User.Identity.Name);
}
public IEnumerable<Asset> GetAssets(int ownerID)
{
return RavenSession.Query<Asset>().Where(x => x.OwnerId == ownerID);
}
This method is decorated with the
[Authorize] attribute. This mechanism was known previosly in WCF. ASP.NET checks for the cookie within this request and if no cookie is present the request is rejected. Getting the current user and all it's assets is a metter of two linq queries using the
RavenSession. which has to be opened before.
Opening RavenDB session
All the controllers inherit from a base controller called
RavenApiController. This controller opens the session to RavenDB when it is initialized and than potentially saves the changes to the database when the work is finished. The
dispose method of the controller is the last method which is invoked when the work is over.
protected override void Initialize(System.Web.Http.Controllers.HttpControllerContext controllerContext)
{
base.Initialize(controllerContext);
if(RavenSession == null)
RavenSession = WebApiApplication.Store.OpenSession();
}
protected override void Dispose(bool disposing)
{
base.Dispose(disposing);
using (RavenSession)
{
if (RavenSession != null)
RavenSession.SaveChanges();
}
}
public Object Post(Charge value, int assetID)
{
var owner = ObtainCurrentOwner();
var asset = GetAsset(assetID,owner);
value.Id = asset.GenerateChargeId();
if (asset.Charges == null)
{
asset.Charges = new List<Charge>();
}
asset.Charges.Add(value);
return GetResponse(value, asset, true);
}
Since RavenDB provides changes tracking, there is no need to perform additional work. RavenDB will notice, that new charge was added to the Charges collection and when SaveChanges function is invoked on the Raven session, the new charge will be persisted to the database. As it has been explained before, the SaveChanges is invoked while disposing the controller.
Note that if you want to acceess the Charge object in the future, you need to give it and ID. RavenDB does generated IDs only for documents, but not for any inner objects. The solution here is to give each Asset and id counter for the charges, which is incremented any time new asset is added.
The FrontEnd
All the logic on the client side resides in ViewModel classes. I assume you are familiar with MVVM pattern. If not you can still continue reading, while the understanding should be intuitive if you have worked with MVC frameworks before. The parent ViewModel and the one which aggregates others is the OwnerViewModel. The ViewModels build up a hierarchy similary as the domain objects.
The OwnerViewModel has to get all the assets and build an AssetViewModel around each received Asset. The data is retrieved from the server as JSON using asynchronous request.
function OwnerViewModel() {
var self = this;
$.extend(self, new BaseViewModel());
self.assets = ko.observableArray([]);
self.selectedAsset = ko.observable([]);
self.isBusy(true);
self.message('Loading');
$.ajax("/../api/assets", {
type: "get", contentType: "application/json",
statusCode: {
401: function () { window.location = "/en/Account/LogOn" }
},
success: function (data) {
var mappedAssets = $.map(data, function (item) {
return new AssetViewModel(self, item);
});
self.assets(mappedAssets);
}
});
}
You can notice that this ViewModel calls jQuery's $.extend method right at the begining of the function. This is one of the ways to express inheritance in JavaScript. JavaScript is prototype based language. The objects derive directly from other objects, not from classes. The extend method basically copies all properties from the object specified in the parameter.
All of my ViewModels have certain common properties such as busy or message. These are help variables which I use on all ViewModels to visualize progress or show some info messages in the GUI. The BaseViewModel is a good place to define these common properties. Notice also the selectedAsset property, which holds the currently selected AsseetViewModel (imagine user selecting one line in the table of assets).
Wihtout further examination let's take a look at the AssetViewModel. There are several self-epxlanatory properties such as address, price and similar. What is more interesting are the arrays of Rents and Charges. These are observable arrays of ViewModels which are filled during the construction of the AssetViewModel object. The data to this object is passed from the OwnerViewModel. The asset also holds its value to the owner in the parent property.
function AssetViewModel(parent,data) {
var self = this;
$.extend(self, new BaseViewModel());
self.lat = ko.observable();
self.lng = ko.observable();
self.city = ko.observable();
self.country = ko.observable();
self.zipCode = ko.observable();
self.address = ko.observable();
self.name = ko.observable();
self.charges = ko.observableArray([]);
self.rents = ko.observableArray([]);
self.parent = parent;
if (data != null) {
self.isNew(false);
self.name(data.Name);
//update all asset data here
//fill the charges collection - note the rents are filled similarly
if (data.Charges != null) {
self.charges($.map(data.Charges, function (data) {
return new ChargeViewModel(self, data);
}));
}
}
}
To sum it up: When the OwnerViewModel is loaded in the screen, it immidiately starts HTTP request to obtain all the data. It will recieve a JSON which contains all the assets, each asset containing the charges and rents inside. This JSON is parsed respectively by OwnerViewModel, AssetViewModel and Charge and RetnViewModel. At the end the complete hierarchy of ViewModels is created on the client side which copies exactly the server side.
Before detailing the last missing ViewModels (Rents and Charges), let's take a look at the first part of the View. The parent layout is defined in _Layout.cshtml however the part mastered by Knockout is defined in the Index.cshtml file. The left side menu is composed of two smaller menus. One which contains the list of properties with the possibility to create new one and another one which allows to switch over details of the selected property. Here is the View representing the first menu:
<div class="well sidebar-nav">
<li class="nav-header">Property list:</li>
<ul class="nav nav-list" data-bind="foreach:assets">
<li><a data-bind="text:name,click:select" href="#"></a></li>
</ul>
<ul class="nav nav-list">
<li class="nav-header">Actions:</li>
<li><a href="#" data-bind="click: newAsset"><i class="icon-pencil"></i>@BasicResources.NewProperty</a></li>
</ul>
</div>
Foreach binding was used in order to render all the apartments. For each apartment an anchor tag is emitted. The text of this tag is bound to the name of the apartment and the click actions is bound to the select function. The creation of new asset is handled by the newAsset function of the OwnerViewModel.
The second part of the menu is defined directly as html. Three anchor tags are render, each of them pointing to different tab, using the same url pattern. For example the URL "#/{property-name}/overview" should navigate to the "Overview" tab of the property with given name.
Client side routing is used, in order to execute certain actions depending on the accessed url. In order to enable client side rendering Path.JS library is used. The attribute binding of knockout is used to render the correct anchor tag.
<div class="well sidebar-nav" data-bind="with:selectedAsset">
<ul class="nav nav-list">
<li class="nav-header" data-bind="text:name"></li>
<li><a data-bind="attr: {href: '#/' + name() + '/overview'}"><i class="icon-pencil"></i>Overview</a></li>
<li><a data-bind="attr: {href: '#/' + name() + '/charges'}"><i class="icon-arrow-down"></i>Charges</a></li>
<li><a data-bind="attr: {href: '#/' + name() + '/rents'}"><i class="icon-arrow-up"></i>Rents</a></li>
</ul>
</div>
You can also notice, that the with binding was used to set the current asset view model as the parent for the navigation div. The right part simply contains all of the 3 tabs (overview, charges or rents), only one of them visible at time. In order to separate the content into multiple files, partial rendering of ASP.MVC is used.
<div id="assetDetail" class="span9" data-bind="template: {data: selectedAsset, if:selectedAsset, afterRender: detailsRendered}">
<div id="overview">
@Html.Partial("Overview")
</div>
<div id="charges">
@Html.Partial("Charges")
</div>
<div id="rents">
@Html.Partial("Rents")
</div>
</div>
Again the with binding is used as the selected apartment's ViewModel is used to back-up this part of the view.
Now let's go back to the ViewModels.
ChargeViewModel and
RentViewModel have a same ancestor which is called
ObligationViewModel. Since both rents and charges how some common properties such as the amount or the regularity, a common parent ViewModel is good place to define them.
The most interesting part of
ChargeViewModel is the
save function which uses JQuery to emit a HTTP request to the
ChargesController. As previously described, two different operations are exposed with the same url, one for creation (HTTP PUT) another for update (HTTP POST). The ViewModel uses a
new flag to distinguish these two cases. Before the request is executed, the ViewModel uses
Knockout.Validation plugin to perform this check with the
errors property.
self.save = function () {
if (self.errors().length != 0) {
self.errors().showAllMessages();
return;
}
self.isBusy(true);
data = self.toDto();
var rUrl = "/../api/charges?assetID=" + self.parent.id();
if (self.isNew())
var opType = "post";
else
var opType = "put";
$.ajax(rUrl, {
data: JSON.stringify(data),
type: opType, contentType: "application/json",
success: function (result) {
self.isBusy(false);
self.message(result.message);
if (self.isNew()) {
self.update(result.dto);
parent.charges.push(self);
}
}
});
}
When there are no validation errors, the object which will be sent to the server is created from the ViewModel by the toDto method. It does not make sense to serialize the whole ViewModel and send it to the server. In the toDto method the ViewModel is converted to an JSON object which can be directly mapped to the server side entity. The ajax method of jQuery is called, which creates new HTTP request.
When the response from the server comes back, the callback is executed, which performs several operations. Besides updating the GUI-helpful variables the callback performs two different operations. If the new charge was added, then it has to be added also to the parent ViewModel(appartment - represented by AssetViewModel). The new charge also recieved the server side ID which has to be updated. All other properties are already up-to-date.
Removing charge
The delete operation is very simple. Only asset and charge ids have to be supplied to the controller. If the operation has succeed, then againg the collection of charges inside AssetViewModel has to be updated.
self.remove = function () {
$.ajax("/../api/charges/" + self.id() + "?assetID=" + self.parent.id(), {
type: "delete", contentType: "application/json",
success: function (result) {
self.isBusy(false);
parent.charges.remove(self);
parent.selectedCharge(null);
}
});
};
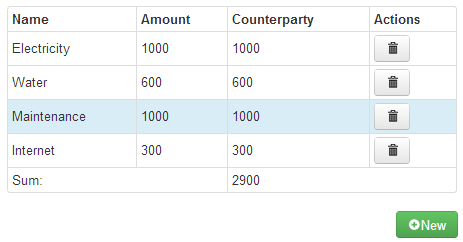
Charges View
The charges view is classic master detail view. We have list of items on the left side and the detail of one of the items on the right. A table of charges is rendered using the foreach binding and then the currently selected charge is rendered in a side div tag using the with binding.
<div class="row-fluid">
<table class="table table-bordered table-condensed">
<tbody data-bind="foreach: charges">
<tr style="cursor: pointer;" data-bind="click: select">
<td style="vertical-align: middle">
<div data-bind='text: name'></div>
</td>
<td style="vertical-align: middle">
<div data-bind="text: amount"></div>
</td>
<td style="vertical-align: middle">
<div data-bind="text: amount"></div>
</td>
<td>
<button type="submit" class="btn" data-bind="visibility: !isNew(), click:remove"><i class="icon-trash"></i></button>
</td>
</tr>
</tbody>
</table>
</div>
You can see, that the click action of the table row is bound the the
select method of the
ChargeViewModel
Using the KoExtensions
As you can see there is a pie chart representing the charges repartition. This chart is rendered using
D3JS, more specifically by a special binding of a small project of mine called
KoExtensions. The rendering of the graph is really simple. The only thing to do is to use the
piechart binding which is part of KoExtensions. This binding takes 3 parameters: the collection of the data to be rendered, transformation function to indicate which values inside the collection should be used to render the graph and the last but not least the initialization parameters.
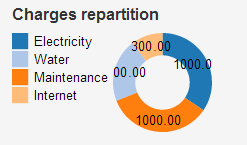
<div data-bind="piechart: charges, transformation:obligationToChart"></div>
function obligationToChart(d) {
return { x: d.name(), y: d.amount() };
}
In order to render the graph, the KoExtensions binding needs to know which value in one concretion collection item specifies the with of each arc in the pie chart and which value is the title. Internally these values are called simply
x and
y. The developer has to specify function which for each item in the collection returns {
x,y} pair. The transformation function uses the
name and the
amount values of the charge. The initialization parameters of the chart are not set, so the default once are used.
Bootstrap style date-time picker
Bootstrap does not contain a date-time picker nor is it on their roadmap. Luckily the community came up with a solution. I have used the one called
bootstrap-datepicker.js. Since I needed to use it with Knockout, I have came up with another special binding which you can find in KoExtensions, it's usage is fairly simple.
<div class="controls">
<input type="text" data-bind="datepicker:end">
</div>
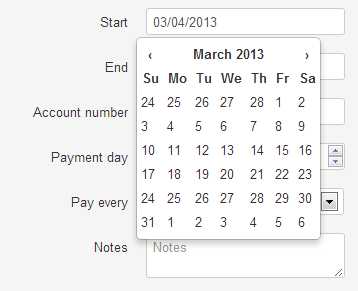
Binding to the map
The last usage of KoExtensions is the rendering of the map containing all the assets in the left hand bar. I have created a binding which enables the rendering of one or more ViewModels on the map, by specifing which property contains the latitude and longitude values. Here the binding is used withing a foreach binding, in order to display all the appartments in the map.
<div class="row-fluid">
<div data-bind="foreach: assets">
<div data-bind="latitude: lat, longitude:lng, map:map, selected:selected">
</div>
</div>
<div id="map" style="width: 100%; height: 300px">
</div>
</div>
The map has to be initialized the usual way as described in the official google maps tutorial, the binding does not take care of this. This enables the developer to define the map exactly the way he likes. Any other elements can be rendered on the same map, simply by passing the same map object to other bindings. The selected property which is passed in the binding tells the binding which variable it should update or which function to call when one element is selected in the map.
Knockout Validation and Bootstrap styles
One of the Knockout's features which make it a really great tool, is the
styles binding, providing you with the ability to associate one concrete css style to an UI component, if some condition in the ViewModel was met. One of the typical examples is giving the selected row in a table a highlight.
<tr style="cursor: pointer;" data-bind="css : {info:selected},click: select">...</tr>
Bootstrap provides styles for highlighting UI components such as textboxes and are ready to use.
Knockout-Validation is a great plugin which extends any observable value with
isValid property, and enables the developer to define rules which will determine the value of this property.
self.amount = ko.observable().extend({ required: true, number: true });
self.name = ko.observable().extend({ required: true });
<div class="control-group" data-bind="css : {error:!name.isValid()}">
<label class="control-label">Name</label>
<div class="controls">
<input type="text" placeholder="@BasicResources.Name" data-bind="value:name">
<span class="help-inline" data-bind="validationMessage: name"></span>
</div>
</div>
<div class="control-group" data-bind="css : {error:!amount.isValid()}">
<label class="control-label">@BasicResources.Amount</label>
<div class="controls">
<input type="text" placeholder="@BasicResources.Amount" data-bind="value: amount">
<span class="help-inline" data-bind="validationMessage: amount"></span>
</div>
</div>
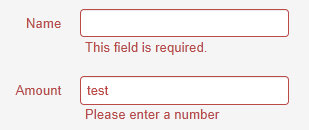
By combining Bootstrap with Knockout-Validation, we can achieve a very nice effect of highlighting when the value is invalid.
What is not described in this article
I did not describe every line of code, but since the project is available at my Github account, you can easily examine it. There are interesting parts at which you might take a look at: JavaScript unit tests, integration test for WebAPI Controller, bundles to regroup and minimize several JS files. Also please not, that the code is not perfect I have used it to play around, not to create a production ready application.
Summary
I think that the frameworks which I have used are all great at what they do. RavenDB in a .NET project is extremely not-present. You don't even have to think about your data storage layer. I know that this DB has much more to offer, but I did not dig to it enough to be able to talk about performance or optimization it provides, but I will definitely check it out later.
KnockoutJS is great at UI data binding. It does not pretend to do more but it does that perfectly. There is not a better tool to declaratively define UI and comportement. And any-time there is some challenging task to do, Knockout usually provides an elegant way to achieve it (like css style binding for the validation).
D3.js even though I did not use it a lot is very powerfull. You can visualize any data any way you want. The only minus might be it's size.
And bootstrap is finally a tool which enables us to get out
usable UI in
reasonable time, without having a designer at our side. This was not really possible before. Go and use them.







