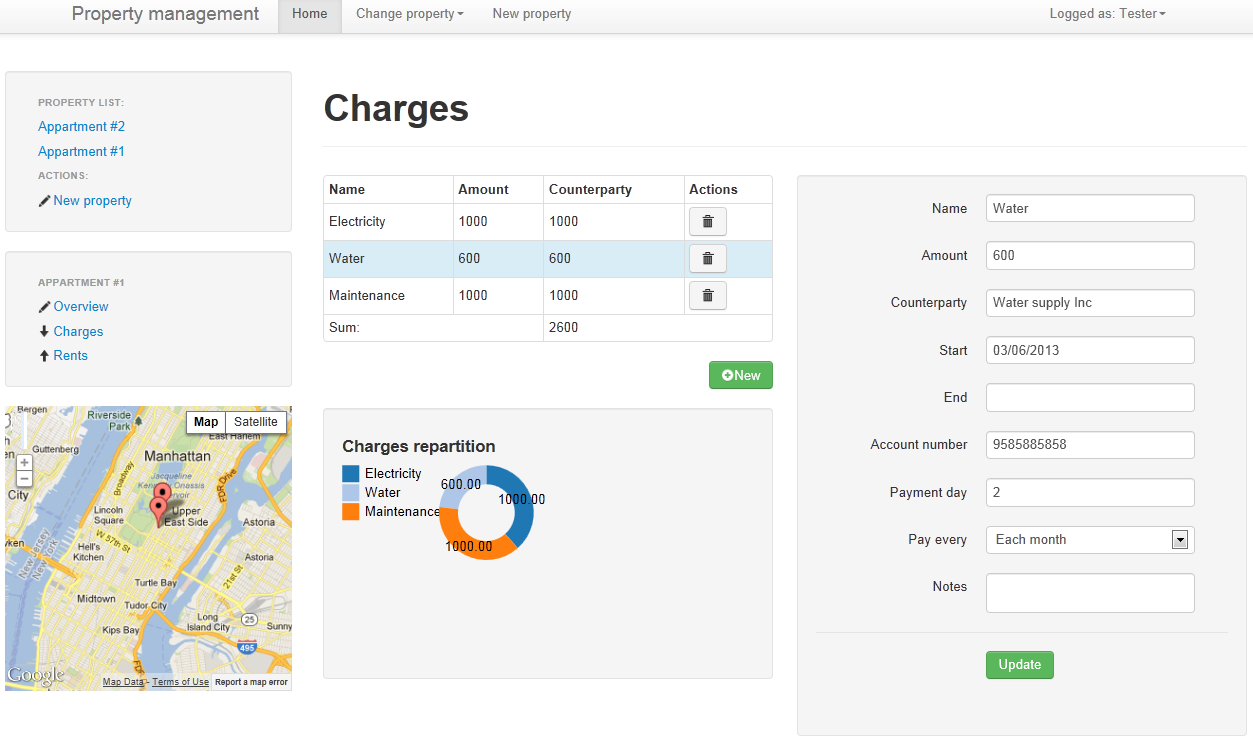
Few months ago I tried to learn a bit about GPU programming and I took notes a started to write this post. I am publishing this now even though it's not complete, however being too busy, I am not sure whether I will have the time to get back to this later.
Since couple years CUDA (*2007) and OpenCL (*2008) have established themselves as standard frameworks for parallel programming on the GPU. In 2011 new framework came to the landscape of GPGPU programming, which does not compete on the same level, but rather represents new abstraction between the GPU and the developer.
AMP stands for Accelerated Massive Parallelism and it is an open C++ standard. The implementation of AMP provided by Microsoft consists of three main features:
- C++ language features and compiler
- Runtime
- Programming framework containing classes and functions to facilitate parallel programming
As well as OpenCL and unlike CUDA, AMP is a standard not only for GPU programming but for any data-parallel hardware. Typical example of such a hardware is the vector unit of standard CPU, capable of executing SIMD (Single Instruction Multiple Data) instructions. Or in the near future a cloud based cluster. AMP is an abstraction layer which can be used to target different devices from different vendors.
The following diagram depicts how AMP C++ fits to the world of GPGPU programming.

Microsoft has implemented AMP on top of DirectCompute technology and it is the only production ready implementation. Currently there are also two Proof Of Concepts AMP implementations Shelvin park project done by Intel and open source modification of the LLVM compiler (more information here). Needless to say that the adoption of such standard will depend a lot on whether these implementations will be taken further and whether we will have real implementation based on CUDA.
First look at the code
Without further introduction let's take a look at the classical "Hello World" of GPGPU programming: Addition of elements of two vectors (here without the boiler plate code).
parallel_for_each(e,[=](index<2>idx) restrict(amp){
c[idx] = a[idx] + b[idx];
});
If you have ever tried out OpenCL or CUDA, you should find this piece of code less verbose and quite easy to read. That is the result of the main ideas behind AMP C++:
- Full C++ - unlike CUDA or OpenCL, AMP is not a C like dialect.
- Minimalist API - AMP hides as much as it can from the developer.
- Future proofed - the API is designed for heterogeneous programming. In the future GPU should be only one of it's usages. It aims to be a standard for programming on distributed systems.
Before going futher with more examples we have to provide basic description of GPU architecture as it is crutial to understanding certain parts of AMP
GPU architecture
Here I will give a high level overview of the GPU architecture. If you are already familiar with the GPU architecture, feel free to skip this section.
Currently there are two main producers of GPU chips: NVidia and ATI (AMD). A little behind comes Intel. Each of them constructs graphic cards with different architecture. Moreover the architectures change significantly with the realease of any new version. Nevertheless certain concepts are shared by all of them. I will describe here shortly the NVidias Fermi and ATIs Cypress architecture. The succesor of Fermi is called Kepler.
Processor architecture
The GPU is composed of hundreds of pipelined cores. The cores are grouped to computation units. NVidia calls these units Symmetric Multiprocessors. Each computation unit is assigned a unit of work.

ATI uses slightly different abstraction. Similary to NVidia the "cores" are grouped to Symmetric Multiprocessors, however each core is called Thread Processor and is a capable of executing VLIV (Very Long Instruction Word) instructions. It has therefore 4 arithmetic logical units and one Special Function Unit. The compiler has to find independent operations and construct the VLIW instruction. If the compiler is not able to find these independent operations than one or more of the ALUs will not be performing any operation.

Memory access
The GPU has a global memory which can be accessed by all cores. This access is quite costly (hundreds of cycles). Each simetric multiprocessor in turn has a small scratch-pad memory which is called usually local memory. This memory can be accessed only by the threads running on the given SM. The access to local memory is much cheaper (around 10 cycles). This memory can either take a role of a cache or can be managed by the developer directly. In addition each core has its own general purpose registers, used to perform the computations.
GPUs usually run computations on data which is accessed only once, unlike CPUs where the same memory pages are often used repetively. For this reason it is better for the developer to control the local memory. That's why historically the local memory did not act as cache on GPUs. However this will probably change in the future, and some form of caching will be provided by the GPU directly.
Scheduling
Scheduling is essential because it allows the effective usage of the processor. Since the memory access is expensive, other operations might be executed while the processor is waiting for the data to come. NVidia processors have "costless" context switching, so while one thread is blocked other can take over. Therefore the number of threads scheduled might affect the computation performance, while if not enough threads are available for scheduling some might be waiting for the memory page loads.
The programming models comparison:
These architectural concepts are used by NVIDIA and ATI. Each of the 3 GPU programming models (CUDA, OpenCL, AMP) can has its own dialects and namings. The following table shows the terms used by all three technologies. We will discuss the AMP terms used in this table later in the article.
| Term | CUDA | AMP C++ | OpenCL |
| Basic unit of work | thread | thread | work-item |
| The code executed on one item | kernel | kernel | kernel |
| The unit processing one group of working units | Streaming multiprocessor | - | Compute unit |
| Cache-style memory accessible by grouped threads | shared memory | tile static memory | local memory |
| Group of working units sharing local memory | warp | tile | work-group |
The tools offered by each framework
Now when the architecture of GPU has been described we can define the tools which each framework needs to provide. In the next part of the article I will try to describe how AMP adresses these issues.
- Tell the compiler which part of the code will be offloaded to the GPU
- Provide constructs to work with multidimensional vectors
- Provide a way to transfer the data between the GPU and the CPU
- Give the developer tools to write efficient programs. That is to address GPU specific problems such as memory access
AMP detailed description and more examples
Here is again the first example with the little of boiler plate code that we have to write to make it work:
void vectorsAddition_Parallel(vector<float> vA, vector<float> vB, vector<float>vC, int M, int N){
extent<2> e(M,N);
array_view<float,2> a(e, vA), b(e,vB);
array_view<float,2> c(e, vC);
//capture of the data using array_view -> results in the copy of the data into the accelerators memmory.
parallel_for_each(e,[=](index<2>idx) restrict(amp){
c[idx] = a[idx] + b[idx];
});
}
The code sent and executed on the GPU is called "kernel" (here one line of code). The kernel is passed to the GPU in the form of lambda expression through the parallel_for_each method. This static method is the entry point to AMP. This method takes two parameters parallel_for_each(extent, delegate). The extend parameter describes the dimensionality of the data. The delegate encapsulates the logic which will be executed. The logic is usually defined as an anonymous function which takes the index<N> as parameter. The computation is expressed using this index on previously defined arrays. In the aboved sample the c[idx] = a[idx] + b[idx] simply means, that for each index (and index goes from 0,0 to N,N since it is two dimensional index) the elements at these positions of the arrays will be added and stored in the array c. Of course that this code is not executed sequentially, but instead defined as a set of vector operations which are scheduled on the GPU
The extent as well as the index parameter are templated. The index identifies one unique position in N dimensional array. The extent describes the dimensions of the computation domain.
The array_view class takes care of the copy of the data to and from the GPU. When the computation is finished, the synchronized method is called on the vC array_view. This call will synchronize the C vector with the array_view. To give the complete information, note also that there is an array class which behaves similary, having few inconvenience and advantages. This post gives a good comparison of these two classes.
The following example ilustrates some of the dificulties which we can have when writing parallel code. The code simply sums all the elements in an array in parallel way. The parallelization of addition of items requires a bit of engineering, even though the sequential solution is evident. Here I am using a technique which is not really efficient but demonstrates the principles of parallelization. Several techniques to parallelize the task are described in this article.
float sumArray_NaiveAMP(std::vector<float> items){
auto size = items.size();
array_view<float, 1> aV (size, items);
for(int i=1;i<size;i=2*i){
parallel_for_each(extent<1>(size/2), [=] (index<1> idx) restrict(amp)
{
aV[2*idx*i] = aV[2*idx*i] + aV[2*idx*i+i];
});
}
return aV[0];
}
The algorihtm adds each two neighbouring items and stores the result in the first item. This has to be repeated until the addition of the whole array is stored in the first position in the array. As described in the mentioned article this approach is not memory efficient and optimizations exists. Note also that the synchronize method is not called on the array_view at the end of the computation. That is because, we don't want the modified data to be copied back from the GPU to the main memory, we are only interested in the sum of the elements.
Another example here is the computation of the standard deviation of the values in an array. First step is the computation of the avarage of the array. To obtain the avarege we have to first add the elements in the array (using the previous example). Having the average, we can obtain the distance of each element from the average. Once we have the distance of each element, we have to make another addition before taking the final square root and obtaining the standard deviation.
float standatd_deviation(vector<float> vA) {
float size = vA.size();
extent<1> e((int)size);
vector<float> vDistance(size);
array_view<float, 1> a(e, vA);
array_view<float, 1> distance(e,vDistance);
float dispertion = 0;
float total = 0;
total = sumArray_NaiveAMP(vA);
float avg = total/size;
parallel_for_each(
e,
[=](index<1> idx) restrict(amp) {
distance[idx] = (a[idx] - avg)*(a[idx] - avg);
});
distance.synchronize();
dispertion = sumArray_NaiveAMP(vDistance);
return sqrt(dispertion/size);
}
This algorithm has 3 parallelized parts: the two sums at the beginning and at the end, and than the calculation of the distance of each element.
Looking at both of the preceding examples, you might be wondering why the code is so complex and you might think that the sum of the elements in the array could be just written as:
float sum = 0;
parallel_for_each(
e,
[=](index<1> idx) restrict(amp) {
sum+=a[idx];
});
However if you think a bit more, you should understand that the code in the parallel_for_each runs essential in the same time. All the parallel threads would like to increment the sum variable at the same time. In addition to that, this code would not even compile, while the modifications of variables captured "by value" are not allowed and in this example the sum variable is captured by value. If you are not familiar with the different capture types refer to this page.
Here is one more example which ilustrates how index and extent work, it is the second hello world of parallel computing: matrix multiplication. This example come from this MSDN page.
void matrixMultiplicationWithAMP(vector<float> &vC, vector<float> vA, vector<float> vB, int M, int N) {
extent<2> e(M,N);
array_view<float, 2> a(e, vA);
array_view<float, 2> b(e,vB);
array_view<float, 2> product(e, vC);
parallel_for_each(
product.extent,
[=](index<2> idx) restrict(amp) {
int row = idx[0];
int col = idx[1];
for (int inner = 0; inner < M; inner++) {
product[idx] += a(row,inner) * b(inner,col);
}
}
);
product.synchronize();
}
Note that the resulting vector vC i passed to the method as reference, since it's content is modified by the synchronize call. Also note, that this example assumes that the vectors passed to the function contain two dimensional array of size (N,N). Since AMP supports multidimensional indexes, AMP runs over all the columns and all the rows automatically, just by iterating over the two-dimensional index. The inner loop just sums the multiplications of the elements in the current row of the left matrix and the current column of the right matrix.
Moving the data between GPU and CPU
As mentioned before, the array_view and array classes are used to transfer the data between the CPU and GPU. The array class directly copies the data to the GPUs global memory. However the data from the array has to be then sent manually back to the CPUs memmory. On the other hand the array_view class works as a wrapper. The vector passed to the array_view will in the background copy the data from and to the vector which is passed in as parameter.
Memory access and manipulation on AMP
As described above, the developer has to address the GPU and adapt the algorithm to the architecture. This basically means minimize the access to global memmory and optimize the threads to use the local memmory. This process is called tiling in the AMP's parlance and the local memmory is called tile-static memory.
If the developer does not define any tiling, the code will be tiled by default. In order to use the local memory efficiently, algorithm has to be tiled manualy. Parallel_for_each method has a second overload which accepts tile_extent as a parameter and the code receives tiled_index in the lambda. Similary as the extend the tile_extend specifies the dimensionality of the computation domain, but also separates the whole computation domain into several tiles. Each tile is than treated by one symetrical multiprocessor, therefor all the threads in the tile can share the local memory and benefit from the fast memory access. If you want to read a bit more about tiling visit this page.
About the future of AMP
As said at the beginning AMP is a standard and as any standard it is dependent of it's implementations. Currently there are two existing implementations of the AMP standard. Microsoft implemented AMP on top of Direct Compute technology. Direct Compute is a part of Microsoft's DirectX suite, which was originally suited only to multimedia programming. Microsoft added DirectComputed to the DirectX suite in order to enable GPGPU programming and with AMP C++ provides an easy way to manipulate the API. The second implementation is very recent and was developed by Intel under the code name Shelvin Park. This implementation builds on top of OpenCL.Summary
Clearly the success of the standard depends on whether other implementations targeting CUDA and OpenCL will emerge. Microsoft cooperated with NVidia and AMD during the development of the API. The idea of having a clear C++ standard to define the parallel computation is great. Latest C++ is quite modern language and provides nice constructs, so actually the programming using AMP C++ is quite fun and not that much pain.
Links
Introduction and few samples Parallel Programing in Native Code - blog of the AMP teamGeForce GTX 680 Kepler Architecture
Comparison between CUDA and OpenCL (though little outdated 2011-06-22)