In a set of data points, outliers are such values that theoretically should not appear in the dataset. Typically these can be measurement errors or values caused by human mistakes. In some cases outliers are not caused by errors. These values affect the way that the data is treated and any statistics or report based on data containing outliers are erroneaus.
Detecting these values might be very hard or even impossible and a whole field of statistics called Robust Statistics covers this subject. If you are further interested into the subject please read Quantitative Data Cleaning For Large Databases written by Joseph M. Hellerstein from UC Barkeley. Everything that I have implemented here is taken from this paper. The only thing that I have added to that are two aggregates for SQL Server which help efficiently get the outliers and extreme values from the data stored in SQL Server and a simple tool to chart data and distribution of data using JavaScript
Theory
Any dataset can be characterized by the way the data is distributed over the whole range. The probability that a single point has given value in the dataset is defined using the probability distribution function. The Gaussian standard distribution is only one among many distribution functions, I won't go into statistics basics here, but let's consider only the standard distribution for our case.
In the Gaussian distribution the data points are somehow gathered around the "center", and most values fall not far. Rare are the values really far away from the center. Intuitively the ouliers are points very far from the center. Consider the following set of numbers which represent in minutes the length of a popular song:
3.9,3.8,3.9,2.7,2.8,1.9,2.7,3.5, 4.4, 2.8, 3.4, 8.6, 4.5, 3.5, 3.6, 3.8, 4.3, 4.5, 3.5,30,33,31
You have probably spotted the values 30,33 and 31 and you immediately identify them as outliers. Even if the Doors would double the length of their keyboard solo we would not get this far.
The standard distribution can be described using the probability density function. This function defines the probability that the point will have given value. The function is defined with two parameters: the center and the dispersion. The center is the most common value, the one around which all others are gathered. The dispersion describes how far the values are scattered from the center.
The probability that a point has a given value, provided that the data has the Gaussian distribution is given by this equation:

We can visualize both the theoretical and the real distribution of data. The distribution probability density function is continuous and thus can be charted as simple line. The distribution of the real data in turn can be visualized like a histogram.
The following graphics were created using KoExtensions project, which is a small mediator project making Knockout and D3 work nicely together.
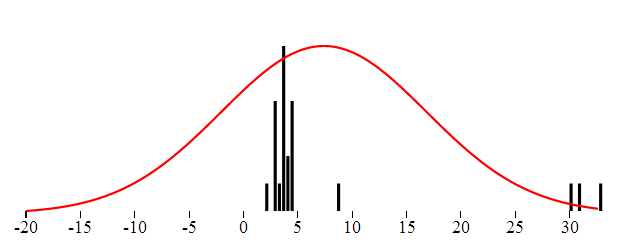
In perfect world the center is the mean value. That value is probably not a part of a data set but represents the typical value. The seconds measure which describes how far from the center the data is dispersed is called standard deviation. If we want to obtain the standard deviation from data we take the distance of each point from the center, square these values add them together and take square root. So we actually have all we need to get the distribution parameters from the data.
This approach of course has one main flaw. The mean value is affected by the outliers. And since the dispersion is deduced using the mean and outliers affect the mean value, the dispersion as well will be affected by them. In order to get a description of the dataset not affected by the extreme values one needs to find robust replacements for the mean and the dispersion.
Robust Center
The simplest and very efficient replacement for the mean as the center of the data is the median. Median is such value that half of the points in the dataset are smaller are bellow. That is if the data set consists of even number of samples, we just need to order the values and take mean of the two values in the middle of the ordered array. If the data consist of odd number of values then we take the element exactly in the middle of the ordered data. The before mentioned paper describes two more alternatives: trimmed mean, winsorized mean. Both of these are based on the exclusion of marginal values and I did not used them in my implementation.
Let's take the median of the given dataset and see if the distribution function based on it fits better the data. Even though the center is now in correct place the shape of the function does not fit completely the data from the histogram. That is because the variance is still affected by the outliers.

Robust Dispertion
Standard variance takes into account the the distance of all the numbers from the center. To rule out the extreme values, we can just use the median of distances. The outlier's distance from the center is much bigger than other distance and by taking the median of all distances we can get rid of outlier's influence over the dispersion. Here is the distribution function using this Robust type of dispersion. This characteristic is called MAD - Median Absolute Deviation.

Detecting the outliers
Now that we have the value of "real" center and "real spread" or dispersion we can state that the outlier is a value which differs "too much" from the center, taking into account the dispersion. Typically we could say that the outliers are such values that have a distance from center greater or equal to 10 * dispersion. The question is how to specify the multiplication coefficient. There is a statistics method called Hampel Indetifier which gives a formula to obtain the coefficient. Hampel identifier labels as outliers any points that are more than 5.2 away from the MAD. More details can be found here.

The overall reliability of this method
A question which might arise is up to which kind of messy data this method can be used. A common intuition would say that definitely more than the half of the data has to be "correct", in order to be able to detect the incorrect ones. To be able to measure the robustness of each method of detecting outliers, statisticians have introduced a term called Breakdown point. This point states which percentage of the data can be corrupted in order for given method to work. Using the Median as the center with the MAD (Median Absolute Deviation) has a breakdown point of 1/2. That is this method works if more than half of the data is correct. The standard arithmetic mean has a BP = 0. It is directly affected by all the numbers and one single outlier can completely move the data.
SQL implementation
In order to implement detection of outliers in SQL, one needs to first have the necessary functions to compute the mean, median and dispersion. All these functions are aggregates. Mean (avg) and Dispersion (var) are already implemented in SQL Server. If you are lucky enough to use SQL Server 2012 you can use the built-in median aggregate as well. The robust dispersion however has to be implemented manually even on SQL Server 2012.
Implementing aggregates for SQL Server is very easy, thanks to the predefined Visual Studio template. This templates will create a class for you which implements the IBinarySerializable interface and is decorate with couple attributes defined in the Microsoft.SqlServer namespace.

This class has 4 important methods:
- Init - anything needed before starting the aggregation
- Accumulate - adding one single value to the aggregate
- Merge - merging two aggregates
- Terminate - work to be done before returning the result of the aggregate
Here is the example of the Median aggregate
private Listld; public void Init() { ld = new List (); } public void Accumulate(SqlDouble value) { if (!value.IsNull) { ld.Add(value.Value); } } public void Merge(Median group) { ld.AddRange(group.ld.ToArray()); } public SqlDouble Terminate() { return Tools.Median(ld); }
Note that some aggregates can be computed iteratively. In that case all the necessary logic is in the Accumulate method and the Terminate method can be empty. With Median this is not the case (even though some iterative estimation methods exist. For the sake of the completeness, here is the implementation of median that I am using. It is the standard way: sorting the array and taking the middle element or average of the two middle elements. I am returning directly SqlDouble value, which is the result of the aggregate.
public static SqlDouble Median(Listld) { if (ld.Count == 0) return SqlDouble.Null; ld.Sort(); int index = ld.Count / 2; if (ld.Count % 2 == 0) { return (ld[index] + ld[index - 1]) / 2; } return ld[index]; }
Implementing the Robust variance using the MAD method is very similar, everything happens inside the Terminate method.
public SqlDouble Terminate()
{
var distances = new List();
var median = Tools.Median(ld);
foreach (var item in ld)
{
var distance = Math.Abs(item - median.Value);
distances.Add(distance);
}
var distMedian = Tools.Median(distances);
return distMedian;
}
That implementation is directly the one described above: we take the distance of each element from the center (median) and than we take the median of the distances.
Outliers detection with the SQL aggregates
Having implemented both aggregates, detecting the outlier is just a matter of a SQL query - giving all the elements which are further away from the center than the variance multiplied by a coefficient.
select * from tbUsers where Height > ( Median(Height) + c*RobustVar(Height)) or Height < (Median(Height) - c*RobustVar(Height))
You will have to play with the coefficient value c to determine which multiplication gives you the best results.
JavaScript implementation
The same can be implemented in JavaScript. If you are interested in a JavaScript implementation you can check out the histogram chart from KoExtensions. This charting tool draws the histogram and the data distribution function. You can than configure it to use either Median or Mean as the center of the data as well as to use MAD, or standard variance to describe the dispersion.
KoExtensions is based on Knockout.JS and adds several useful bindings and the majority of them to simplify charting. Behind the scenes the data is charted using D3.
To draw a histogram chart with the distribution and detecting the outliers at the same time one needs just few lines of code
<div id="histogram" data-bind="histogram: data, chartOptions : {
tolerance : 10,
showProbabilityDistribution: true,min : -20,
expected: 'median',
useMAD: true,
showOutliers: true}">
var exData = [3.9,3.8,3.9,2.7,2.8,1.9,2.7,3.5, 4.4, 2.8, 3.4, 8.6, 4.5, 3.5, 3.6, 3.8, 4.3, 4.5, 3.5,30,33,31];
function TestViewModel() {
var self = this;
self.data = ko.observableArray(exData);
}
var vm = new TestViewModel();
ko.applyBindings(vm);
initializeCharts();
Knockout.JS is a JavaScript MVVM framework tool which gives you all you need to create bi-directional binding between the view and the view model, where you can encapsulate and unit test all your logic. KoExtensions adds a binding call "histogram", which takes simple array and draws a histogram. In order to show the probability function and the outliers one has to set the options of the chart as shown in the example above.